













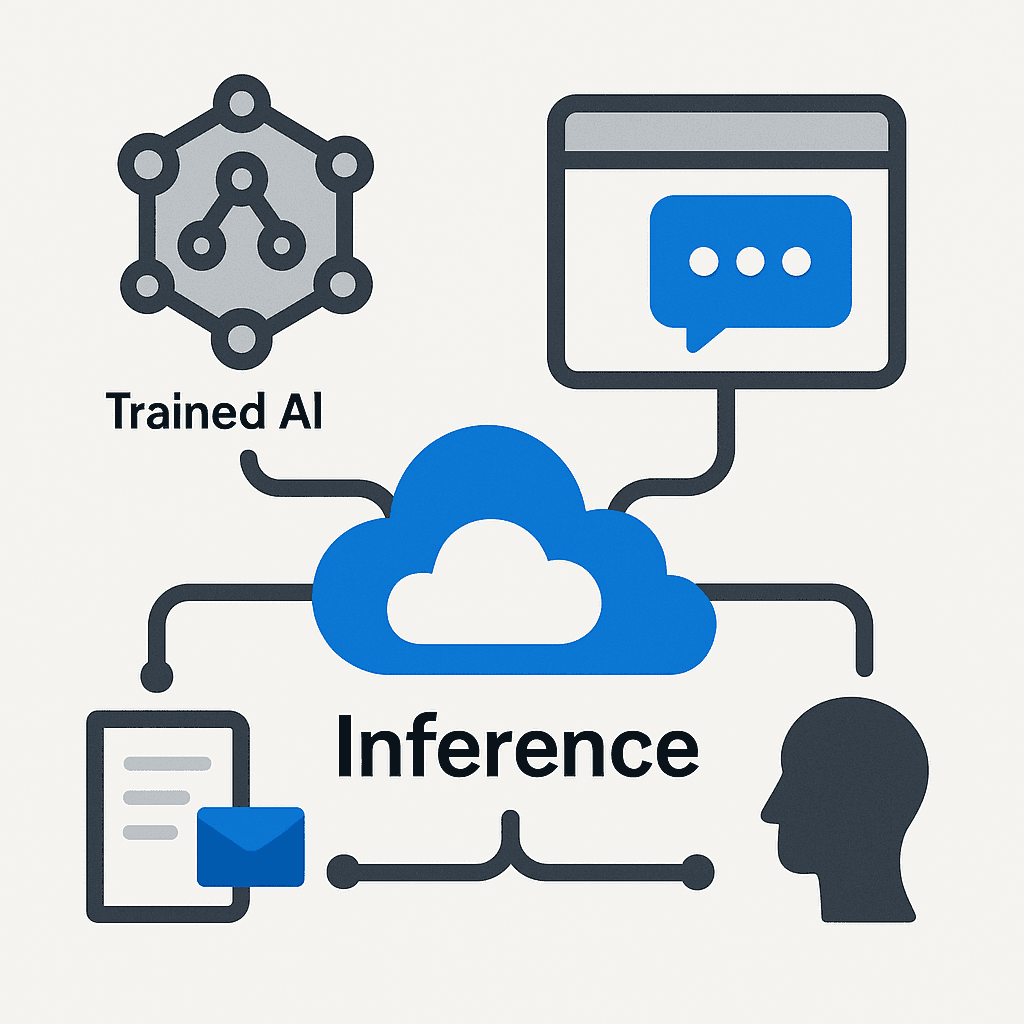
Lorsqu’on parle d’intelligence artificielle générative — comme ChatGPT, Copilot ou Gemini — le terme « inférence » désigne le processus par lequel un modèle préalablement entraîné génère une réponse à partir d’une entrée utilisateur (le prompt).
Entraînement et inférence sont donc deux moments distincts :
- L’entraînement est une phase coûteuse (temps, calcul, données) où le modèle « apprend » des motifs et relations à partir d’énormes corpus textuels.
- L’inférence est la mise en œuvre de ce savoir pour raisonner à la volée, sans « apprendre » de nouvelles choses (sauf si explicitement configuré pour le faire).
Modèle vs Application : une différence cruciale
- Le modèle (ex. GPT-4o, Gemini Pro) est comme une bibliothèque interne. Il ne « sait » rien de spécifique sur vous par défaut, mais il contient des connaissances générales figées à la date de son entraînement (appelée cut-off).
- L’application (ex. ChatGPT, Copilot, Grok) est une couche d’orchestration. Elle :
- Gère votre session de chat,
- Peut se connecter à des bases de données externes (plugins, API, fichiers),
- Peut avoir une mémoire conversationnelle pour se rappeler de vos interactions passées (si activée),
- Peut utiliser les données pour améliorer le modèle, selon la politique du fournisseur.
Un exemple simple d’orchestration
Prenons ChatGPT avec Copilot comme scénario :
1. Vous tapez un prompt : « Résume-moi ce document Word. »
2. L’application orchestration va :
- Lire le document,
- Découper l’information,
- Passer ces données au modèle,
- Collecter la réponse,
- Vous la restituer.
3. Aucune « connaissance » n’est stockée dans le modèle à ce stade.
4. Selon le paramètre de collecte, vos données peuvent être retenues pour réentraîner le modèle ou non.
Que font les grands acteurs aujourd’hui ?
Voici une comparaison simple et détaillée sur la manière dont les données utilisateur sont utilisées et sur la mémoire.
| Fournisseur / Application | Modèle utilisé | Mécanisme de mémoire | Données utilisées pour réentraîner ? | Exemple concret d’orchestration |
|---|---|---|---|---|
| ChatGPT (OpenAI) | GPT-4o, GPT-4-turbo | Mémoire conversationnelle (opt-in sur certains plans) | Oui, sauf si l’utilisateur désactive la collecte. Les sessions pro peuvent désactiver l’historique. | Vous discutez, téléversez un fichier → l’application orchestre un contexte → le modèle répond. |
| Copilot (Microsoft) | Basé sur GPT-4o mais orchestré dans M365 | Pas de mémoire conversationnelle propre ; la mémoire est contextuelle (ex. historique mail) | Non, vos données pro ne servent pas à entraîner GPT. Contrats B2B garantissent isolation. | Vous demandez « Résume mes emails » → Copilot lit Outlook → prépare un contexte → appelle le modèle → vous affiche le résumé. |
| Grok (xAI / Elon Musk) | Basé sur LLM de xAI | Pas de mémoire persistante encore claire (dépend de l’intégration X) | Potentiellement oui, usage interne pour améliorer le modèle | Vous posez une question sur X → Grok accède au flux X → fournit une réponse contextualisée. |
| Gemini (Google) | Gemini 1.5 Pro, Ultra | Mémoire conversationnelle expérimentale (opt-in) | Oui, sauf pour données sensibles et régionales (ex. UE plus restrictive) | Vous posez une question → Gemini peut rechercher dans vos docs Google Drive → fournit la réponse. |
| Meta AI | Llama | Pas de mémoire conversationnelle pour l’instant | Oui, les messages peuvent contribuer à l’amélioration sauf opt-out | Vous posez une question sur Instagram ou WhatsApp → Meta AI génère une réponse mais ne « retient » pas votre historique conversationnel complet. |
Un mot sur la confidentialité
- Pour Microsoft Copilot, c’est très clair : les données restent dans le tenant M365, sous contrat de service. Aucun usage pour réentraîner GPT.
- Pour ChatGPT, l’option « Chat History & Training » vous permet de bloquer l’usage de vos chats pour l’entraînement futur.
- Google, Meta et Grok précisent qu’ils peuvent réutiliser vos données pour améliorer leurs modèles par défaut, mais souvent vous pouvez demander l’opt-out (variable selon la loi locale).
Points à retenir
- Le modèle ne s’enrichit pas de vos prompts en temps réel. Il génère une réponse en « inférence ».
- Les applications apportent le contexte, orchestrent les API et gèrent la mémoire conversationnelle.
- La réutilisation de vos données dépend du fournisseur, des paramètres et du contrat.
- Dans un contexte professionnel, préférez les versions gérées (Copilot M365) qui garantissent l’isolation des données.
Microsoft 365 Copilot : une orchestration d’inférence hautement sécurisée
L’inférence dans Copilot : une chaîne maîtrisée
Quand vous utilisez Copilot dans Word, Outlook, Teams ou Excel :
- Vous restez dans l’écosystème Microsoft 365, avec des accès régulés par Azure Active Directory (AAD) et votre politique de gouvernance.
- Le modèle LLM (ex. GPT-4-turbo) est hébergé et orchestré dans un environnement contrôlé, via Azure OpenAI Service.
- L’inférence ne modifie jamais le modèle : le modèle reste figé. Les requêtes sont des sessions éphémères.
Exemple simple :
Vous demandez à Copilot : « Rédige une synthèse des 5 derniers emails de mon équipe sur le projet X. »
- Copilot lit vos données Exchange Online,
- Prépare un prompt étendu,
- Envoie ce contexte à l’API Azure OpenAI,
- Reçoit une réponse,
- Vous restitue la réponse dans votre tenant, sans stocker le résultat ailleurs.
Les données ne quittent jamais le périmètre sécurisé
Voici le principe fondamental :
- Pas de transfert vers l’OpenAI public : Les données restent dans Azure, dans une région conforme à votre tenant Microsoft 365 (ex. EU, Canada).
- L’accès aux données se fait en temps réel, sans réplication hors de votre environnement.
- Microsoft applique la confidentialité par conception :
- Pas d’entraînement du modèle avec vos données professionnelles.
- Les logs d’activité sont utilisés uniquement pour le diagnostic de service (et souvent minimisés/anonymisés).
- Vous restez maître de vos journaux d’audit via Purview.
Copilot ne « retient » rien de façon autonome
- Copilot ne dispose pas de mémoire conversationnelle persistante comme ChatGPT.
- Le « contexte » est recréé à chaque prompt à partir :
- De vos contenus M365 : SharePoint, OneDrive, Teams, Outlook…
- Des autorisations dynamiques (si vous n’avez pas accès, Copilot non plus).
- Il n’y a aucune base de données Copilot qui accumule vos requêtes. Tout dépend de la source d’origine et de vos droits.
Orchestration étape par étape
Voici une vue simplifiée :
1. L’utilisateur émet une demande (ex. « Résume cette présentation PowerPoint. »)
2. L’application Copilot appelle les API Graph pour récupérer le fichier dans SharePoint.
3. Un orchestrateur Copilot prépare le prompt final enrichi de contexte.
4. Ce prompt est envoyé au modèle hébergé dans Azure OpenAI, pas sur Internet public.
5. La réponse est renvoyée au service Copilot qui vous l’affiche dans l’application (Word, Outlook, Teams).
6. Les logs restent dans le périmètre Microsoft 365 pour compliance (Audit, Purview).
Points clés à retenir
- Zéro apprentissage sur vos données.
- Zéro fuite vers un modèle public.
- Orchestration 100 % intégrée au modèle de sécurité M365.
- Vous contrôlez les accès avec vos groupes AAD, DLP, Sensitivity Labels.
- Copilot applique votre gouvernance :
- Si un document est restreint, Copilot ne peut pas le lire.
- Si vous limitez la durée de rétention des logs, c’est respecté.
Pourquoi c’est unique ?
Contrairement à ChatGPT (OpenAI) ou Gemini (Google) qui nécessitent une vérification manuelle pour exclure vos données de l’entraînement futur, Microsoft 365 Copilot est conçu comme un service B2B sécurisé où vos données restent cloisonnées.
L’orchestration (Graph, Copilot Services) est sous SLA (Service Level Agreement) et auditée selon les standards Microsoft 365 (ISO, GDPR, FedRAMP…).
Résumé en une phrase
Microsoft 365 Copilot, c’est une inférence orchestrée dans votre tenant, respectant votre modèle Zero Trust, sans risque de fuites vers l’extérieur, et sans apprentissage automatique sur vos contenus d’entreprise.
Conclusion
L’inférence, c’est la partie visible de l’IA : vous donnez un prompt, l’application orchestre, le modèle répond.
Mais la vraie maîtrise, c’est de comprendre où vont vos données, comment elles nourrissent (ou non) les modèles futurs, et de savoir paramétrer votre usage (historique, mémoire, opt-out).
En résumé : un modèle est une bibliothèque, une application est une porte d’entrée, et vous êtes le bibliothécaire qui décide de ce qu’on garde ou non pour demain.








