














Pendant des décennies, les organisations ont fonctionné avec une hypothèse implicite: si un document existe, alors l’information est disponible, et si l’information est disponible, alors la connaissance existe. Cette hypothèse n’a jamais été totalement vraie, mais elle était fonctionnelle tant que les humains restaient les principaux consommateurs de l’information.
L’arrivée des agents IA d’entreprise change radicalement la donne. Microsoft 365 Copilot, par exemple, ne « lit” pas les documents comme un humain. Il exploite un ensemble de signaux issus du Microsoft Graph, des index de recherche, des métadonnées, des relations entre contenus, et des permissions. Ce mécanisme de grounding, l’ancrage sur les données réelles de l’organisation, est explicitement documenté par Microsoft.
Cela signifie une chose extrêmement concrète: l’IA ne crée pas la connaissance. Elle amplifie ce qui existe déjà. Si les sources sont fiables, structurées et gouvernées, l’IA devient un multiplicateur d’expertise. Si les sources sont incohérentes, obsolètes ou non validées, l’IA devient un multiplicateur d’incertitude.
Pourquoi la gestion documentaire traditionnelle n’est plus suffisante
Les standards internationaux n’ont jamais réduit la gestion documentaire à du stockage. L’ISO 9001 définit l’information documentée comme un actif devant être contrôlé sur tout son cycle de vie: création, validation, mise à jour, diffusion, conservation et suppression.
Reférence: ISO (Guidance on Documented Information (ISO 9001 clause 7.5)).
Ce qui a changé avec les outils modernes comme SharePoint, OneDrive et Teams, ce n’est pas la nécessité de contrôle. C’est la facilité de publication. La rareté de la publication jouait autrefois un rôle de filtre naturel. Aujourd’hui, ce filtre doit être reconstruit par la gouvernance.
Microsoft documente clairement que l’architecture de l’information dans SharePoint doit permettre la gouvernance, la « découvrabilité » et la cohérence des contenus.
Référence: SharePoint Information Architecture.
Dans un environnement IA-first, cette architecture devient un composant technique, pas seulement organisationnel.
Le responsable de la connaissance: un rôle redevenu central
Dans l’écosystème documentaire historique, l’archiviste ou le documentaliste assurait implicitement la qualité de la connaissance. Dans les environnements numériques modernes, ce rôle doit être explicitement recréé.
Le responsable de la connaissance agit comme point de contrôle entre l’information brute et la connaissance validée. Il garantit la cohérence entre les exigences métier, les exigences réglementaires et les exigences techniques des plateformes numériques.
Ce rôle devient critique parce que les agents IA utilisent directement le contenu d’entreprise comme base de raisonnement.
L’ordre logique réel des contrôles de connaissance
Si l’on assemble les exigences issues de l’ISO, des recommandations Microsoft et des standards de gouvernance des données, un ordre logique naturel apparaît. Ce n’est pas un ordre arbitraire. Il suit la logique du cycle de vie informationnel et des architectures modernes.
Voici un pipeline réaliste basé sur les pratiques officiellement documentées.
flowchart TD
A([Source d'information créée ou capturée])
--> B{Source fiable et autorisée?}
B -- Non --> Z([Connaissance NON validée])
B -- Oui --> C{Classification et sensibilité appliquées?}
C -- Non --> Z
C -- Oui --> D{Métadonnées obligatoires complètes?}
D -- Non --> Z
D -- Oui --> E{Stockage dans un référentielgouverné<br/>ex: SharePoint?}
E -- Non --> Z
E -- Oui --> F{Contrôle d'accès conforme<br/>Zero Trust / moindre privilège?}
F -- Non --> Z
F -- Oui --> G{Versioning et historisation activés?}
G -- Non --> Z
G -- Oui --> H{Validation par responsable de la connaissance?}
H -- Non --> Z
H -- Oui --> I{Normalisation documentaire<br/>et cohérence terminologique?}
I -- Non --> Z
I -- Oui --> J{Révision périodique planifiée?}
J -- Non --> Z
J -- Oui --> K{Rétention et cycle de vie définis?}
K -- Non --> Z
K -- Oui --> L{Audit et traçabilité activés?}
L -- Non --> Z
L -- Oui --> M{Qualité sémantique compatible IA?}
M -- Non --> Z
M -- Oui --> Y([Connaissance VALIDÉE exploitable par IA])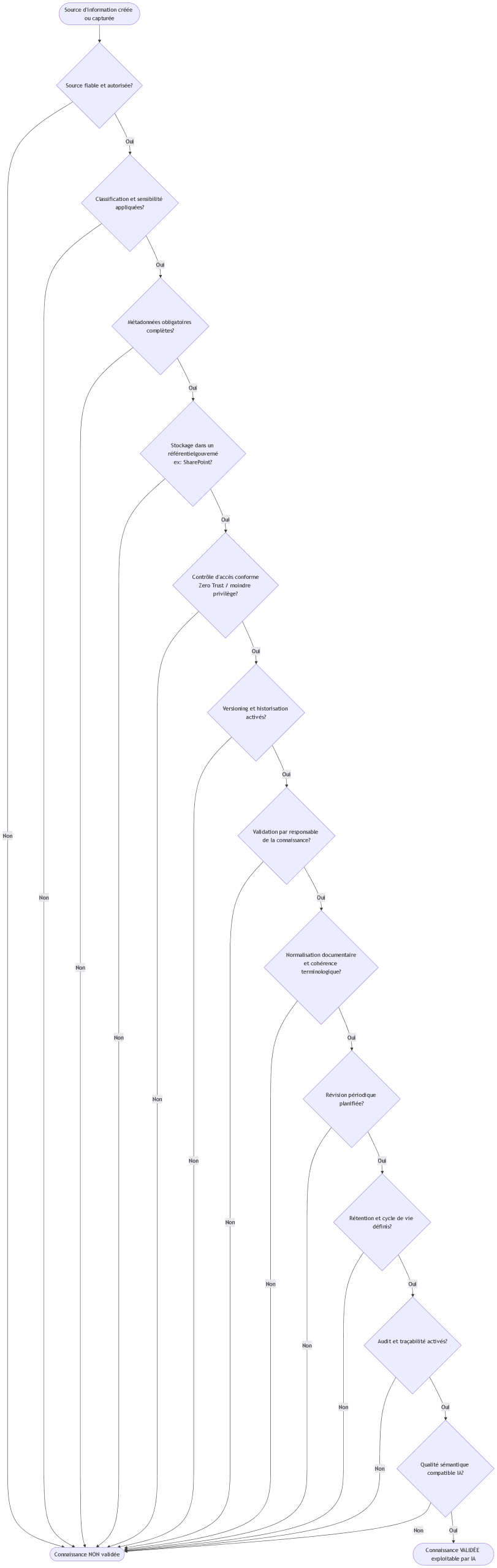
Pourquoi cet ordre est cohérent avec les sources officielles
L’ordre proposé dans le diagramme ne vient pas d’un choix arbitraire ou d’une préférence technologique. Il découle d’une convergence entre plusieurs référentiels internationaux : gouvernance des données, qualité de l’information, normes ISO, standards de cybersécurité, et architectures modernes des plateformes collaboratives.
L’idée fondamentale est simple mais souvent sous-estimée : on ne peut pas gouverner, protéger, exploiter ou automatiser ce qui n’est pas d’abord qualifié et compris.
A) La fiabilité de la source comme fondation absolue
La fiabilité de la source est la première étape logique. Les frameworks de gouvernance des données comme le DAMA-DMBOK (Data Management Body of Knowledge) insistent sur la notion de trust in data origin. La qualité ne commence pas lors de l’exploitation. Elle commence à la création ou à la capture.
La norme ISO 8000 sur la qualité des données va dans le même sens: une donnée ne peut être considérée de qualité que si son origine, son contexte et sa validité sont maîtrisés.
Dans un contexte connaissance, cela signifie que toute information doit pouvoir répondre à des questions simples:
- D’où vient-elle?
- Qui l’a produite?
- Dans quel contexte métier?
- À quel moment?
Sans ces éléments, l’information peut exister, mais elle ne peut pas devenir connaissance.
Références:
- DAMA-DMBOK2 – Data Quality & Data Governance chapters
- ISO 8000 – Data Quality Management
B) La classification et la sensibilité comme prérequis à toute décision de protection
Une fois la source validée, l’étape suivante est l’identification de la nature de l’information.
Avant de décider comment protéger, partager ou exploiter une information, il faut savoir ce qu’elle est et ce qu’elle représente en termes de risque.
Historiquement, cette logique existait déjà dans les organisations: les documents papier comportaient des mentions visibles comme Confidentiel, Restreint, Interne, souvent en filigrane. Cela créait un signal visuel immédiat de sensibilité.
Les labels de sensibilité modernes sont l’équivalent numérique de ces pratiques historiques, mais avec des capacités automatisées: chiffrement, restriction d’accès, protection contre le partage externe, etc.
Microsoft Purview formalise cette logique via Information Protection et Sensitivity Labels.
Référence: Sensitivity Labels et Information Protection
C) Métadonnées et structuration
Une fois l’information identifiée et classifiée, elle doit être structurée.
Les métadonnées ne sont pas un “bonus documentaire”. Elles sont le socle de :
- la recherche,
- la classification,
- la gouvernance,
- la traçabilité,
- et désormais l’exploitation par les IA.
Dans les référentiels DAMA et ISO, la structuration des données fait partie intégrante de la qualité informationnelle.
Dans l’écosystème Microsoft, cette structuration repose notamment sur:
- les colonnes de métadonnées,
- les types de contenu,
- le Term Store (taxonomie contrôlée).
Référence: Managed Metadata
D) Le stockage dans un référentiel gouverné
Le stockage dans un référentiel gouverné correspond aux bonnes pratiques. Dans l’écosystème Microsoft, SharePoint s’impose comme référentiel documentaire structuré et gouverné.
Mais il faut être très clair: mettre un document dans SharePoint ne transforme pas son contenu en connaissance.
Le moteur de recherche SharePoint est performant, mais il reste dépendant de plusieurs contraintes techniques:
- capacité d’indexation des formats,
- taille des fichiers,
- fréquence de crawl,
- profondeur d’analyse sémantique.
Les formats Microsoft (DOCX, PPTX, XLSX) sont optimisés pour l’indexation, mais l’analyse complète des contenus volumineux reste coûteuse en ressources. Dans la pratique, certains contenus peuvent être indexés partiellement.
C’est une limite technique normale des systèmes de recherche documentaire à grande échelle.
Références: SharePoint Search Overview, Semantic Index for Copilot
E) Le contrôle d’accès
Une fois l’information stockée, l’accès doit être contrôlé selon le principe du moindre privilège.
Ce principe est au cœur des architectures Zero Trust. Il stipule que l’accès doit être explicitement validé, même à l’intérieur du système d’information.
Référence: NIST SP 800-207 – Zero Trust Architecture
Dans un contexte IA, ce point devient critique. Les agents IA respectent les permissions. Une mauvaise gouvernance d’accès devient donc immédiatement visible dans les résultats générés.
F) Versioning et historisation
La gestion des versions n’est pas seulement une fonctionnalité technique. Elle constitue une preuve de gouvernance.
Elle permet:
- la traçabilité,
- la justification des décisions,
- la conformité réglementaire,
- la compréhension de l’évolution métier.
Référence: Versioning SharePoint
G) Validation par un responsable
Les normes qualité ISO insistent toutes sur la responsabilité humaine dans la validation des informations critiques.
Dans SharePoint, cela se traduit par les workflows d’approbation.
Référence: Content Approval
H) Normalisation documentaire
La normalisation facilite:
- l’extraction automatique,
- la compréhension humaine,
- la cohérence terminologique,
- l’analyse par les IA.
Dans le monde francophone, cette logique est historiquement portée par:
- les normes AFNOR documentaires en France,
- les recommandations OQLF pour le Québec,
- les référentiels qualité ISO.
I) Révision périodique
Une connaissance non révisée devient progressivement une hypothèse.
L’ISO 9001 impose explicitement le maintien à jour des informations documentées.
Référence:
ISO 9001 — Clause 7.5 Documented Information
J) Rétention et cycle de vie
Une information doit avoir un cycle de vie défini. Sinon, elle devient du bruit historique.
Référence: Retention Policies
K) Audit et traçabilité
L’audit permet:
- la conformité réglementaire,
- l’analyse d’incident,
- la transparence organisationnelle.
Référence: Audit in Microsoft 365
L) Qualité sémantique
Enfin, la qualité sémantique conditionne l’exploitation par les agents IA.
Les technologies comme Microsoft Syntex permettent l’extraction structurée d’information à partir des documents.
Référence: Syntex Document Processing
La couche sémantique
La transformation réelle vers la connaissance passe par la structuration sémantique.
Les standards du Web sémantique du W3C, notamment OWL, définissent comment représenter des concepts métier et leurs relations.
Reférence: W3C (OWL Web Ontology Language).
Une ontologie permet de décrire:
- les objets métier
- leurs relations
- leurs contraintes
- leurs dépendances
- leurs contextes d’usage
C’est cette structure qui permet aux agents IA de raisonner sur le contenu plutôt que de simplement le lire.
Le lien direct avec Microsoft 365 Copilot
Microsoft indique clairement que Copilot utilise les contenus organisationnels comme base de raisonnement via Microsoft Graph.
Cela implique plusieurs conséquences très concrètes:
- Si plusieurs versions contradictoires existent, Copilot peut utiliser les deux.
- Si un document obsolète n’est pas marqué, Copilot peut le considérer valide.
- Si la taxonomie est incohérente, Copilot perd du contexte métier.
- Si la classification est incorrecte, Copilot peut exposer ou masquer des données de manière inappropriée.
La pyramide Information, Connaissance, Savoir-faire
Dans une organisation moderne, il est essentiel de distinguer clairement trois niveaux souvent confondus: information, connaissance et savoir-faire. Cette distinction est devenue critique avec l’arrivée des agents IA, car ces systèmes exploitent principalement la couche “connaissance”, pas les documents bruts ni l’expérience humaine.
A) L’information: la matière première
Un document contient naturellement des informations. Mais un document n’est pas une connaissance.
Un contrat, une procédure ou un rapport contiennent des faits, des règles ou des données brutes.
À ce stade, l’information est dépendante:
- du contexte,
- de l’auteur,
- du moment de création,
- du format.
La première transformation consiste donc à extraire l’information du document.
Important:
Information extraite ≠ Connaissance.
B) La connaissance: information structurée et reliée au métier
L’information devient connaissance lorsqu’elle est:
- structurée sémantiquement,
- rattachée à une ontologie métier,
- validée,
- contextualisée.
Une ontologie métier n’est pas un modèle standard générique.
C’est une représentation spécifique des objets, règles et relations propres à l’entreprise.
Mais un point reste essentiel:
Connaissance ≠ Savoir-faire.
Une organisation peut posséder beaucoup de connaissances documentées et rester incapable de les appliquer efficacement.
C) Le savoir-faire: la connaissance appliquée par l’humain
Le savoir-faire apparaît lorsque la connaissance est transformée par l’expérience humaine:
- logique opérationnelle,
- mémoire des situations passées,
- compréhension des contextes humains,
- capacité d’adaptation.
C’est ce qui permet réellement:
- de livrer,
- de résoudre les exceptions,
- d’optimiser,
- d’innover.
D) De la connaissance à la valeur
Une fois stabilisé par des processus qualité (standards, audits, KPI), le savoir-faire permet:
- la livraison de services et produits,
- la satisfaction client,
- la génération de cash-flow,
- la valorisation de l’entreprise.
La valeur réelle d’une organisation repose sur sa capacité durable à transformer la connaissance en savoir-faire reproductible.
E) La boucle stratégique: capitaliser pour progresser
L’expérience terrain doit ensuite être réinjectée dans:
- la documentation,
- les procédures,
- la formation,
- les référentiels métier,
- les modèles sémantiques.
Cette boucle transforme l’expérience en nouvelle connaissance.
F) Dans l’ère des agents IA
Les agents IA accélèrent l’accès à la connaissance.
Mais ils ne remplacent pas le savoir-faire humain.
La performance moderne repose donc sur la maîtrise complète de cette chaîne:
Document → Information → Structuration → Ontologie → Connaissance → Expérience → Savoir-faire → Valeur → Capitalisation.
C’est cette boucle qui constitue aujourd’hui le cœur invisible de la performance des organisations.
Implémenter ce modèle sans créer une bureaucratie paralysante
La clé n’est pas de tout contrôler. La clé est de définir clairement ce qui doit être gouverné au niveau connaissance.
- Les contenus stratégiques doivent être gouvernés strictement.
- Les contenus de travail peuvent rester flexibles.
- La distinction doit être visible et technique, pas seulement culturelle.
La publication doit redevenir un acte de responsabilité
La transformation la plus importante n’est pas technique. Elle est culturelle.
Publier ne doit pas signifier “rendre visible”.
Publier doit signifier “rendre fiable”.
Dans un environnement dominé par les agents IA, la gestion de la connaissance devient un élément d’infrastructure, au même titre que l’identité numérique ou la cybersécurité.
Le paradoxe fascinant de l’ère IA
Plus les outils deviennent intelligents, plus les organisations doivent devenir rigoureuses sur la qualité de leur connaissance.
L’IA ne remplace pas la gouvernance de la connaissance.
Elle rend son absence immédiatement visible.
Et c’est peut-être l’un des changements les plus profonds de la transformation numérique actuelle : la connaissance cesse d’être un sous-produit du travail. Elle devient une ressource stratégique à part entière, directement exploitable par les humains et par les systèmes intelligents.










