












Il y a des annonces techniques qui ressemblent à de petits détails. Un nouveau format. Une spécification. Quelques fichiers Markdown. Un peu de YAML. Rien de très spectaculaire à première vue.
Et puis, quand on prend le temps de regarder, on comprend que ce n’est pas le format lui-même qui compte. Ce qui compte, c’est le changement de paradigme qu’il rend visible.
C’est exactement ce que je ressens avec l’Open Knowledge Format, ou OKF, publié par Google Cloud en juin 2026.
Je ne vais pas faire semblant : OKF n’est pas encore une révolution industrielle. C’est une spécification en version 0.1. C’est jeune, incomplet, encore expérimental. Mais ce que cette spécification dit de l’avenir de l’intelligence artificielle, de la gestion de la connaissance et de l’intelligence collective est, à mon avis, fondamental.
Parce que le vrai problème des organisations, aujourd’hui, n’est pas seulement de savoir utiliser ChatGPT, Copilot, Claude ou Gemini. Le vrai problème est beaucoup plus profond : nos organisations ne savent pas réellement rendre leur connaissance lisible, transmissible, maintenable et actionnable.
Nous avons des documents partout. Des wikis abandonnés. Des fichiers Word dans SharePoint. Des notes de réunion dans Teams. Des pages Confluence. Des procédures dans des PDF. Des connaissances dans la tête de quelques experts. Des schémas de données dans des catalogues techniques. Des règles métier cachées dans des fichiers Excel. Des décisions stratégiques perdues dans des courriels.
Et au milieu de tout ça, nous demandons à des agents IA de “comprendre l’entreprise”.
Soyons sérieux deux minutes : comment pourraient-ils comprendre quelque chose que l’entreprise elle-même n’a jamais vraiment structuré ?
C’est là qu’OKF devient intéressant.
Ce qu’est OKF, simplement
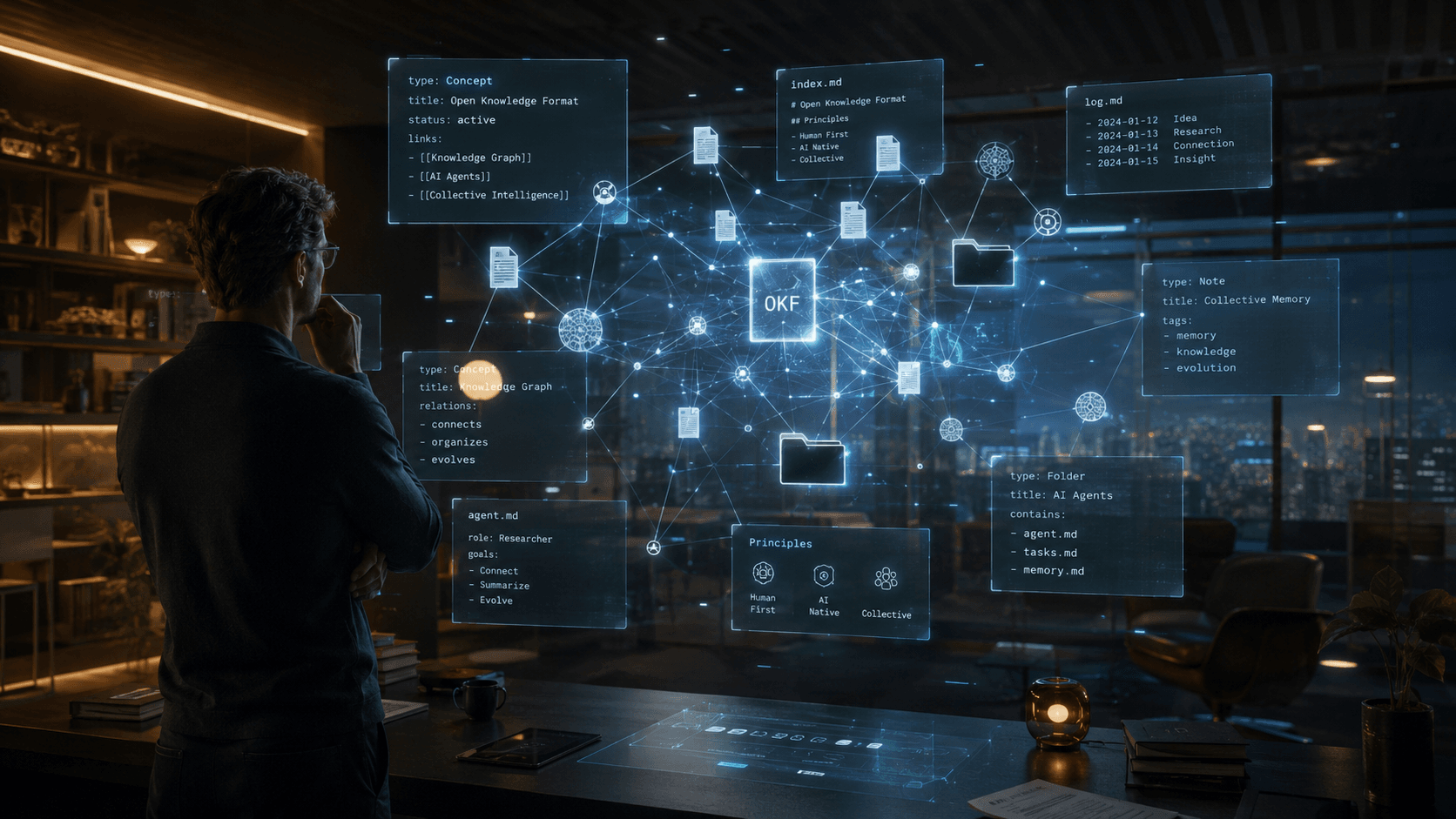
L’Open Knowledge Format est une spécification ouverte proposée par Google Cloud pour représenter de la connaissance sous forme de fichiers Markdown organisés dans des dossiers, avec un bloc de métadonnées YAML au début de chaque fichier.
Autrement dit : OKF propose de transformer une base de connaissance en un ensemble de fichiers texte simples, lisibles par des humains, lisibles par des machines, versionnables dans Git, transportables d’un système à l’autre, et surtout compréhensibles par des agents IA.
Un bundle OKF ressemble à ceci :
knowledge/
├── index.md
├── log.md
├── formations/
│ ├── index.md
│ ├── dialoguer-avec-ia.md
│ └── copilot-pages.md
├── concepts/
│ ├── index.md
│ ├── prompting.md
│ ├── context-engineering.md
│ └── instruction-design.md
├── agents/
│ ├── index.md
│ ├── agent-formateur.md
│ └── agent-recherche.md
└── metriques/
├── index.md
└── taux-adoption-copilot.md
Chaque fichier Markdown représente un concept. Ce concept peut être une formation, une métrique, une table de données, une procédure, une API, une règle métier, un agent, un processus, une décision, une politique interne ou une idée.
Un fichier OKF typique pourrait ressembler à ceci :
---
type: Formation
title: Apprendre à dialoguer avec l’intelligence artificielle générative
description: Formation d’introduction pour apprendre à formuler une demande claire, contextualisée et exploitable auprès d’un assistant IA.
resource: https://intranet.example.com/formations/dialoguer-ia
tags: [ia-generative, formation, prompting, debutant]
timestamp: 2026-06-29T09:00:00Z
---
# Objectif
Cette formation vise à aider les employés à comprendre comment dialoguer efficacement avec un assistant IA génératif.
# Public cible
Employés débutants, formateurs internes, gestionnaires et professionnels souhaitant intégrer l’IA dans leurs tâches quotidiennes.
# Concepts liés
- [Prompting](../concepts/prompting.md)
- [Context Engineering](../concepts/context-engineering.md)
- [Instruction Design](../concepts/instruction-design.md)
# Exemples d’usage
Un participant apprend à transformer une demande vague comme :
> Fais-moi un résumé.
en une demande structurée :
> Résume ce document pour un gestionnaire non technique. Mets en avant les décisions à prendre, les risques et les prochaines étapes. Utilise un ton professionnel et limite la réponse à 500 mots.
# Notes pédagogiques
Cette formation sert de fondation à tous les parcours IA, peu importe l’outil utilisé : ChatGPT, Microsoft 365 Copilot, Gemini, Claude ou un agent métier.
Ce n’est pas spectaculaire. Et justement, c’est toute la force du format.
OKF ne propose pas une nouvelle plateforme propriétaire. Il ne propose pas un nouveau portail de connaissance. Il ne demande pas un SDK obligatoire. Il ne dit pas : “venez enfermer votre savoir dans mon cloud”.
Il dit plutôt : “écrivez votre connaissance dans un format simple, portable, lisible et structuré.”
Et, franchement, c’est exactement ce dont nous avons besoin.
Pourquoi Google s’intéresse à ça maintenant ?
Parce que les modèles d’IA ont progressé très vite, mais ils se heurtent toujours au même mur : le contexte.
Un modèle peut être très bon. Il peut raisonner, synthétiser, reformuler, coder, comparer, planifier. Mais s’il n’a pas accès à la bonne connaissance au bon moment, il produit une réponse faible, générique ou faussement confiante.
C’est le problème du “context assembly” : assembler le bon contexte avant de répondre ou d’agir.
Aujourd’hui, dans une organisation, la connaissance nécessaire à une réponse fiable est dispersée partout :
- dans des bases de données ;
- dans des catalogues de métadonnées ;
- dans des wikis ;
- dans des espaces SharePoint ;
- dans des dépôts Git ;
- dans des documents Office ;
- dans des tickets Jira ou Azure DevOps ;
- dans des conversations Teams ou Slack ;
- dans des fichiers locaux ;
- dans la mémoire de quelques experts.
Lorsqu’un agent IA doit répondre à une question comme :
Comment calcule-t-on le taux d’adoption réel de Microsoft 365 Copilot dans notre organisation ?
il ne suffit pas de faire une recherche plein texte. L’agent doit comprendre :
- quelle est la définition officielle de “taux d’adoption” ;
- quelles sources de données sont autorisées ;
- quelles métriques sont obsolètes ;
- quelles exclusions s’appliquent ;
- quelles équipes sont concernées ;
- quelles décisions antérieures ont été prises ;
- quels tableaux de bord sont fiables ;
- quelles règles de gouvernance encadrent l’analyse.
Le problème n’est donc pas seulement de retrouver un document. Le problème est de comprendre un réseau de connaissances.
Et c’est là qu’OKF devient plus qu’un format de fichier.
OKF propose de représenter la connaissance comme un graphe de concepts lisibles.
Pas seulement une pile de documents. Pas seulement un index. Pas seulement une base vectorielle. Un graphe de concepts humains et agentiques.
OKF n’est pas un RAG de plus
Depuis deux ans, beaucoup d’organisations ont répondu au problème de la connaissance avec une réponse presque automatique : “on va faire du RAG”.
Le RAG, ou Retrieval-Augmented Generation, consiste à permettre à un modèle d’aller chercher des fragments pertinents dans une base documentaire avant de générer une réponse.
C’est utile. Je ne vais pas jeter le RAG à la poubelle. Il a permis de faire un énorme pas en avant. Mais il a aussi un défaut majeur : dans beaucoup d’implémentations, il traite la connaissance comme une matière brute découpée en morceaux.
On prend des documents. On les découpe en chunks. On les vectorise. On cherche les morceaux les plus proches d’une question. On les injecte dans le contexte du modèle. Puis on espère que la réponse sera bonne.
Le problème est évident : l’intelligence du système dépend fortement de la qualité du découpage, de l’indexation, du ranking, de la fraîcheur des documents et de la capacité du modèle à reconstruire le sens à partir de fragments.
C’est un peu comme si, à chaque question, on demandait à l’IA de refaire l’archéologie complète de l’entreprise.
OKF prend le problème autrement.
Au lieu de dire : “voici un tas de documents, débrouille-toi pour retrouver des passages”, OKF dit : “voici des concepts structurés, nommés, reliés et documentés”.
La nuance est énorme.
Un agent qui lit un bundle OKF ne lit pas seulement du texte. Il lit une architecture de connaissance.
Il peut commencer par index.md, voir les grandes familles de concepts, ouvrir une métrique, suivre un lien vers une table de données, puis vers une règle métier, puis vers un runbook, puis vers une formation, puis vers une décision passée.
C’est une logique de navigation cognitive.
Le pattern LLM Wiki : la connaissance qui s’accumule
OKF formalise un pattern qui commençait déjà à émerger : le LLM Wiki.
L’idée est simple, mais puissante : au lieu d’utiliser l’IA uniquement pour chercher dans des documents à chaque question, on lui fait maintenir progressivement une base de connaissance structurée.
Dans ce modèle, l’IA ne se contente pas de répondre. Elle aide à organiser la connaissance.
Quand un nouveau document arrive, elle peut :
- l’analyser ;
- en extraire les concepts importants ;
- créer ou mettre à jour des pages Markdown ;
- ajouter des liens vers les concepts existants ;
- signaler les contradictions ;
- mettre à jour un index ;
- ajouter une entrée dans un journal de changement.
La connaissance ne disparaît plus à la fin d’une conversation. Elle s’accumule.
C’est probablement l’un des changements les plus importants pour les prochaines années.
Nous avons beaucoup parlé de prompt engineering. Puis de context engineering. Puis d’agents. Mais le sujet profond, derrière tout cela, c’est la mémoire organisationnelle.
Une organisation qui n’a pas de mémoire exploitable par ses agents IA va créer des assistants fragiles, génériques, dépendants de recherches ponctuelles et incapables de capitaliser réellement.
Une organisation qui structure sa connaissance dans un format lisible, versionné et interconnecté commence à créer autre chose : une couche de mémoire collective.
Et là, on se rapproche de sujets beaucoup plus ambitieux : intelligence collective, Enterprise Brain, mémoire d’entreprise, agents métiers, gouvernance de la connaissance.
Les composants essentiels d’un bundle OKF
Un bundle OKF repose sur quelques éléments simples.
1. Des fichiers Markdown
Le Markdown est déjà partout dans le monde technique : documentation GitHub, README, wikis, blogs statiques, notes Obsidian, documentation développeur, fichiers d’instructions pour agents.
C’est un format suffisamment simple pour être lu par un humain, et suffisamment structuré pour être traité par une machine.
Un fichier Markdown peut contenir :
- des titres ;
- des listes ;
- des tableaux ;
- des blocs de code ;
- des liens ;
- des citations ;
- des sections structurées.
C’est banal. Et c’est parfait.
La connaissance durable ne devrait pas dépendre d’une interface propriétaire. Elle devrait pouvoir être ouverte dans n’importe quel éditeur de texte.
2. Un frontmatter YAML
Le frontmatter est le petit bloc de métadonnées placé au début d’un fichier.
Exemple :
---
type: Metric
title: Taux d’adoption Copilot
description: Pourcentage d’utilisateurs actifs ayant utilisé Microsoft 365 Copilot au moins une fois durant la période de référence.
tags: [copilot, adoption, mesure, gouvernance]
timestamp: 2026-06-29T10:00:00Z
---
Dans OKF, le champ obligatoire est type.
Les autres champs sont recommandés ou optionnels : title, description, resource, tags, timestamp.
Ce choix est important : OKF est volontairement minimaliste.
Il ne cherche pas à imposer une ontologie universelle. Il ne dit pas : “voici tous les types possibles de connaissance”. Il laisse chaque organisation définir ses propres types.
Une équipe data utilisera peut-être :
BigQuery DatasetBigQuery TableMetricDashboardData Quality Rule
Une équipe de formation utilisera peut-être :
FormationModuleExerciceCompétenceÉvaluationPersona Apprenant
Une équipe produit utilisera peut-être :
FeatureUser StoryDecisionArchitectureRunbook
Cette liberté est nécessaire. Les organisations n’ont pas toutes la même structure mentale.
3. Des liens Markdown entre concepts
C’est ici que les choses deviennent intéressantes.
Dans OKF, un lien Markdown entre deux fichiers crée une relation entre deux concepts.
Exemple :
Le taux d’adoption Copilot est calculé à partir des données décrites dans [Activité utilisateur Copilot](../datasets/activite-utilisateur-copilot.md).
Ce lien n’est pas seulement utile pour un lecteur humain. Il devient aussi un indice de navigation pour un agent.
Le bundle devient progressivement un graphe.
Et dans une organisation, la valeur ne se trouve pas seulement dans les documents. Elle se trouve dans les relations :
- cette métrique dépend de cette table ;
- cette procédure applique cette politique ;
- cette formation couvre cette compétence ;
- cet agent utilise cette source ;
- cette décision remplace cette ancienne décision ;
- cette règle métier contredit cette pratique locale ;
- ce tableau de bord est la référence officielle ;
- cette donnée ne doit pas être utilisée pour cet usage.
La connaissance n’est pas une bibliothèque. C’est un réseau.
OKF rend ce réseau explicite.
4. Des fichiers index.md
Un fichier index.md sert de point d’entrée.
Il permet à un humain ou à un agent de comprendre ce qui existe dans un dossier avant de tout ouvrir.
Exemple :
# Formations IA
- [Apprendre à dialoguer avec l’IA](dialoguer-avec-ia.md) - Formation d’introduction aux requêtes structurées.
- [Copilot Pages](copilot-pages.md) - Formation sur la co-création et la transformation d’une page en livrable.
- [Copilot Notebooks](copilot-notebooks.md) - Formation sur l’organisation de sources et de conversations.
C’est le principe de la divulgation progressive : l’agent n’a pas besoin de charger toute la base de connaissance d’un coup. Il peut lire l’index, identifier les chemins pertinents, puis ouvrir seulement les concepts nécessaires.
Cela compte énormément pour les coûts, la performance et la qualité des réponses.
5. Des fichiers log.md
Le fichier log.md documente l’évolution du bundle.
Exemple :
# Journal des changements
## 2026-06-29
- **Création** : ajout du concept `Formation - Apprendre à dialoguer avec l’IA`.
- **Mise à jour** : ajout de liens entre `Prompting`, `Context Engineering` et `Instruction Design`.
- **Dépréciation** : ancienne définition de la métrique `utilisateur actif` remplacée par la version 2026.
Cela peut sembler secondaire. Ça ne l’est pas.
Dans une base de connaissance vivante, l’historique est essentiel. Sans historique, on ne sait plus pourquoi une définition a changé, quelle règle a été remplacée, quelle hypothèse a été abandonnée.
Et pour un agent IA, un journal de changement peut devenir un outil de contextualisation extrêmement précieux.
Exemple concret : OKF pour un programme de formation IA
Prenons un cas très concret : une organisation veut structurer son offre de formation IA.
Elle a plusieurs cours :
- Apprendre à dialoguer avec l’intelligence artificielle générative ;
- Utiliser Microsoft 365 Copilot dans la conversation ;
- De l’idéation personnelle au travail collectif avec Microsoft 365 Copilot ;
- Utiliser Copilot Pages ;
- Utiliser Copilot Notebooks ;
- Créer des agents dans Microsoft 365 ;
- Vérifier les faits et limiter les hallucinations.
Elle a aussi des concepts transversaux :
- Prompting ;
- Conversation Design ;
- Context Engineering ;
- Instruction Design ;
- Critical Thinking ;
- Fact Verification ;
- Knowledge Curation ;
- Collaborative AI.
Sans OKF, ces éléments risquent de vivre dans des supports PowerPoint, des documents Word, des fiches pédagogiques, des pages SharePoint, des prompts dispersés et des notes personnelles.
Avec OKF, on peut créer un bundle structuré :
ai-training-knowledge/
├── index.md
├── log.md
├── courses/
│ ├── index.md
│ ├── dialoguer-avec-ia.md
│ ├── copilot-conversation.md
│ ├── ideation-au-travail-collectif.md
│ └── creer-agents-m365.md
├── concepts/
│ ├── index.md
│ ├── prompting.md
│ ├── conversation-design.md
│ ├── context-engineering.md
│ ├── instruction-design.md
│ ├── fact-verification.md
│ └── knowledge-curation.md
├── exercises/
│ ├── index.md
│ ├── transformer-demande-vague.md
│ ├── verifier-reponse-copilot.md
│ └── construire-page-copilot.md
└── personas/
├── index.md
├── employe-debutant.md
├── gestionnaire.md
└── formateur-interne.md
Le fichier concepts/context-engineering.md pourrait contenir :
---
type: Concept
title: Context Engineering
description: Discipline qui consiste à fournir à un modèle IA le bon contexte, au bon niveau de détail, au bon moment.
tags: [ia-generative, contexte, prompting, agents]
timestamp: 2026-06-29T09:30:00Z
---
# Définition
Le Context Engineering consiste à concevoir, sélectionner, organiser et maintenir les informations nécessaires pour qu’un modèle IA puisse produire une réponse fiable et utile.
# Différence avec le prompting
Le prompting concerne la formulation de la demande.
Le Context Engineering concerne l’environnement informationnel dans lequel la demande est interprétée.
# Exemples
Un mauvais contexte :
> Résume cette réunion.
Un meilleur contexte :
> Résume cette réunion pour un directeur de programme. Mets en avant les décisions, les risques, les responsables et les prochaines étapes. Ignore les discussions informelles. Utilise les décisions précédentes du projet comme référence.
# Concepts liés
- [Prompting](prompting.md)
- [Instruction Design](instruction-design.md)
- [Fact Verification](fact-verification.md)
# Formations associées
- [Apprendre à dialoguer avec l’IA](../courses/dialoguer-avec-ia.md)
- [De l’idéation personnelle au travail collectif](../courses/ideation-au-travail-collectif.md)
Maintenant, imaginons un agent pédagogique.
Au lieu de lui donner une pile de documents et de lui dire “prépare-moi une formation”, je peux lui dire :
Lis le bundle OKF du programme IA. Prépare un atelier de 90 minutes pour des gestionnaires débutants. Utilise les concepts
Prompting,Context EngineeringetFact Verification. Propose trois exercices pratiques et indique les prérequis.
L’agent n’a pas besoin d’inventer la structure pédagogique. Elle existe déjà dans le bundle.
Il ne repart pas de zéro. Il compose à partir d’une mémoire collective structurée.
OKF pour une métrique métier
Prenons maintenant une métrique.
Dans les organisations, les métriques sont souvent une catastrophe silencieuse. Tout le monde utilise les mêmes mots, mais personne ne parle exactement de la même chose.
“Utilisateur actif”, “adoption”, “engagement”, “productivité”, “satisfaction”, “usage régulier” : ces termes ont l’air simples, mais ils deviennent très vite ambigus.
Un fichier OKF peut clarifier une métrique.
---
type: Metric
title: Taux d’adoption Microsoft 365 Copilot
description: Pourcentage d’utilisateurs éligibles ayant utilisé Microsoft 365 Copilot au moins une fois durant une période donnée.
tags: [copilot, adoption, mesure, gouvernance]
timestamp: 2026-06-29T11:00:00Z
---
# Définition
Le taux d’adoption Microsoft 365 Copilot mesure la proportion d’utilisateurs éligibles ayant utilisé au moins une fonctionnalité Copilot durant la période de référence.
# Formule
```text
Taux d’adoption = utilisateurs actifs Copilot / utilisateurs éligibles Copilot
Inclus
- Utilisation de Copilot Chat.
- Utilisation de Copilot dans Word.
- Utilisation de Copilot dans Excel.
- Utilisation de Copilot dans PowerPoint.
- Utilisation de Copilot dans Outlook.
- Utilisation de Copilot dans Teams.
Exclus
- Utilisateurs sans licence Copilot.
- Comptes de service.
- Comptes de test.
- Utilisations réalisées dans des environnements de démonstration.
Sources de données
- Journal d’activité Copilot
- Référentiel des licences
Risques d’interprétation
Un utilisateur actif n’est pas nécessairement un utilisateur compétent.
Cette métrique mesure une exposition ou une utilisation minimale, pas la profondeur d’adoption ni la qualité des usages.
Métriques liées
- Taux d’usage récurrent Copilot
- Score de maturité IA
- Satisfaction utilisateur Copilot
Ce fichier est utile pour un humain. Mais il est encore plus utile pour un agent.
Si un gestionnaire demande :
> Pourquoi notre adoption Copilot est-elle faible ?
l’agent peut d’abord lire la définition exacte de la métrique, comprendre ses limites, identifier les sources de données, puis éviter une erreur classique : confondre adoption, usage et maturité.
C’est ici que la connaissance structurée devient un garde-fou contre les réponses superficielles.
## OKF et intelligence collective : le point qui m’intéresse vraiment
Ce qui m’intéresse dans OKF dépasse largement Google.
Je vois OKF comme un symptôme d’un mouvement plus profond : nous passons d’une informatique documentaire à une informatique cognitive.
Pendant des années, nous avons produit des documents. Puis nous les avons classés. Puis nous les avons cherchés. Puis nous les avons indexés. Puis nous les avons vectorisés.
Mais nous avons rarement pris le temps de représenter explicitement ce que l’organisation sait.
Or l’intelligence collective ne se résume pas à accumuler des fichiers.
L’intelligence collective suppose que les connaissances puissent circuler, se relier, se contredire, se corriger, se stabiliser, se transmettre et se transformer en action.
OKF propose une petite brique technique qui va exactement dans ce sens.
Il donne une forme à la mémoire collective.
Pas une forme parfaite. Pas une forme définitive. Mais une forme suffisamment simple pour être adoptée, versionnée et maintenue.
Et c’est souvent comme cela que les grands changements commencent : avec des formats modestes.
Markdown était modeste. YAML est modeste. Git était d’abord un outil de versionnement de code. Les fichiers README sont modestes. Les wikis sont modestes.
Mais quand on met ces briques ensemble et qu’on les rend lisibles par des agents IA, on obtient quelque chose de beaucoup plus puissant : une infrastructure de connaissance vivante.
## OKF et les agents : pourquoi cela compte vraiment
Un agent IA n’est pas seulement un chatbot avec des outils.
Un agent doit pouvoir :
- comprendre un objectif ;
- trouver les bonnes informations ;
- choisir les bonnes actions ;
- respecter des règles ;
- utiliser des outils ;
- produire un résultat ;
- éventuellement apprendre ou mettre à jour une connaissance.
Mais pour faire cela correctement, il doit avoir accès à une mémoire fiable.
Aujourd’hui, beaucoup de projets agentiques sont fragiles parce que leur mémoire est improvisée.
On donne à l’agent :
- un prompt système ;
- quelques documents ;
- une base vectorielle ;
- des connecteurs ;
- des outils ;
- parfois une mémoire conversationnelle.
Puis on espère que l’ensemble tiendra.
Mais une mémoire conversationnelle n’est pas une mémoire organisationnelle.
Une base vectorielle n’est pas une gouvernance de la connaissance.
Un connecteur SharePoint n’est pas une architecture cognitive.
OKF peut jouer un rôle très important entre les sources brutes et les agents.
Je peux très bien imaginer une architecture comme celle-ci :
```text
Sources brutes
↓
Documents, réunions, bases de données, procédures, tickets, wikis
↓
Pipeline d’enrichissement
↓
Extraction des concepts, validation humaine, liens, citations, historique
↓
Bundle OKF
↓
Index de recherche, graphe, agents, assistants, copilotes métier
↓
Réponses, actions, recommandations, nouvelles connaissances
Dans ce modèle, OKF n’est pas nécessairement le moteur de recherche. Il n’est pas forcément l’interface utilisateur. Il n’est pas forcément la base de données finale.
Il est la forme canonique de la connaissance curée.
C’est une différence capitale.
Une organisation peut encore utiliser une base vectorielle, un moteur de recherche, un graphe, un index sémantique ou un MCP server. Mais ces éléments deviennent des projections techniques d’une connaissance maintenue ailleurs.
La source de vérité reste lisible.
Et c’est ça qui change tout.
Est-ce qu’OKF remplace les bases vectorielles ?
Non. Pas toujours. Et il faut éviter les raccourcis.
OKF ne remplace pas magiquement toutes les bases vectorielles, tous les moteurs de recherche ou tous les graphes de connaissance.
Mais OKF peut réduire la dépendance à des systèmes opaques.
Dans beaucoup de cas, surtout pour des corpus petits ou moyens, un bundle Markdown bien structuré, avec des index propres, des liens explicites et quelques outils de recherche locale, peut suffire pour donner à un agent un contexte de très bonne qualité.
À plus grande échelle, on aura probablement besoin d’index dérivés :
- index plein texte ;
- index vectoriel ;
- graphe de relations ;
- cache de résumés ;
- moteur de recherche hybride ;
- scoring de fraîcheur ;
- détection de contradictions ;
- validation de liens.
Mais la nuance est essentielle : ces index devraient être des dérivés, pas la source de vérité.
C’est comme dans le développement logiciel. Le code source est la référence. Les fichiers compilés, les artefacts, les caches et les index sont utiles, mais ils ne sont pas la vérité.
Avec OKF, la connaissance peut être gérée comme du code.
Elle peut être :
- revue ;
- validée ;
- versionnée ;
- comparée ;
- fusionnée ;
- documentée ;
- restaurée ;
- auditée.
C’est une approche “knowledge as code”.
Et je pense que ce sera l’un des piliers des architectures IA sérieuses.
OKF, llms.txt, AGENTS.md : il ne faut pas tout mélanger
Dans l’écosystème actuel, plusieurs fichiers et conventions apparaissent.
Il y a robots.txt, qui sert historiquement à donner des indications aux robots d’indexation.
Il y a sitemap.xml, qui liste les URLs d’un site.
Il y a llms.txt, qui propose de fournir aux modèles de langage une sélection de contenus importants et faciles à lire.
Il y a AGENTS.md ou CLAUDE.md, qui donnent des instructions à des agents de développement dans un dépôt.
Et maintenant, il y a OKF.
La différence est importante.
llms.txt pointe vers les contenus importants.
AGENTS.md explique à un agent comment se comporter dans un contexte donné.
OKF représente la connaissance elle-même.
Je peux le résumer ainsi :
robots.txt → ce que les robots peuvent ou ne peuvent pas explorer
sitemap.xml → quelles pages existent
llms.txt → quels contenus lire en priorité
AGENTS.md → comment un agent doit travailler dans un dépôt
OKF → quelle connaissance structurée l’agent peut consommer
Ces formats ne sont pas concurrents. Ils sont complémentaires.
Un site ou une organisation pourrait très bien avoir :
- un
robots.txt; - un
sitemap.xml; - un
llms.txt; - un bundle
/okf/; - un dépôt Git contenant les instructions agents ;
- un moteur de recherche dérivé ;
- un graphe visuel de la connaissance.
La question n’est pas de choisir un seul format magique. La question est de construire une pile de lisibilité pour les humains et les agents.
Ce qu’OKF n’est pas
Il faut aussi être clair sur les limites.
OKF n’est pas une baguette magique.
OKF ne transforme pas automatiquement une organisation confuse en organisation intelligente.
OKF ne corrige pas une mauvaise gouvernance.
OKF ne rend pas vraie une connaissance fausse.
OKF ne remplace pas la responsabilité humaine.
OKF ne garantit pas que les agents liront correctement les fichiers.
OKF n’est pas, à ce stade, un standard universel adopté par tout l’écosystème.
OKF n’est pas non plus un signal SEO qui va faire grimper un site dans Google du jour au lendemain.
Ce dernier point mérite d’être dit franchement, parce que l’industrie adore transformer chaque nouveau format en promesse marketing.
Non, publier un bundle OKF ne va pas soudainement propulser un site dans les résultats de recherche.
La vraie valeur est ailleurs : rendre la connaissance plus lisible, plus portable, plus maintenable et plus exploitable par des systèmes IA.
C’est déjà énorme.
Les risques à ne pas sous-estimer
Dès qu’on permet à des agents de lire et potentiellement d’écrire dans une base de connaissance, on crée de nouveaux risques.
1. La connaissance toxique
Si un agent ingère des sources non fiables et les transforme en pages OKF, la base devient polluée.
Une connaissance fausse mais bien structurée est encore plus dangereuse qu’une connaissance fausse mal rangée. Elle a l’apparence de l’autorité.
Il faut donc des règles de validation.
2. La dérive de la mémoire
Une base de connaissance vivante peut devenir incohérente.
Certaines pages deviennent obsolètes. D’autres se contredisent. Des concepts sont dupliqués. Des liens cassent. Des décisions anciennes restent visibles comme si elles étaient encore valides.
Il faudra des agents de maintenance, mais aussi des humains responsables de la curation.
3. L’injection indirecte
Si un agent peut écrire dans le bundle OKF à partir de sources externes, il peut être manipulé.
Un document malveillant pourrait contenir des instructions cachées visant à modifier la base de connaissance, influencer les futurs agents ou introduire des erreurs.
Il faudra donc séparer clairement :
- les sources brutes ;
- les contenus proposés par l’agent ;
- les contenus validés ;
- les contenus publiés ;
- les contenus autorisés pour les agents de production.
4. La fausse impression de maîtrise
Parce qu’un bundle OKF est propre, structuré et versionné, on peut croire que la connaissance est maîtrisée.
Mais la structure n’est pas la vérité.
La gouvernance reste indispensable : propriétaires de concepts, cycles de révision, niveaux de confiance, citations, historique, processus d’approbation.
OKF fournit une forme. Il ne fournit pas la discipline organisationnelle à lui seul.
Comment je commencerais concrètement
Si je devais mettre en place OKF dans une organisation, je ne commencerais surtout pas par exporter tout SharePoint.
Ce serait la pire idée.
On obtiendrait un gros tas de Markdown mal typé, sans liens intelligents, sans hiérarchie utile et sans gouvernance réelle.
Je commencerais petit.
Étape 1 : choisir un domaine restreint
Par exemple :
- un programme de formation IA ;
- un référentiel de métriques ;
- une documentation produit ;
- un catalogue d’agents ;
- un domaine métier critique ;
- un processus d’onboarding ;
- une base de connaissance support.
Étape 2 : définir les types de concepts
Exemple pour un programme de formation :
types:
- Formation
- Module
- Exercice
- Compétence
- Persona
- Outil
- Concept
- Évaluation
Exemple pour une équipe data :
types:
- Dataset
- Table
- Metric
- Dashboard
- Data Quality Rule
- Business Definition
- Runbook
- Owner
Étape 3 : créer 20 à 30 concepts de haute qualité
Pas 2 000 fichiers générés automatiquement.
20 à 30 concepts vraiment utiles.
Bien nommés. Bien liés. Bien décrits. Avec des exemples. Avec des limites. Avec des propriétaires.
Étape 4 : ajouter un index.md
L’index doit permettre à un humain ou à un agent de comprendre rapidement le contenu.
Étape 5 : ajouter un log.md
Chaque modification importante doit être inscrite.
Étape 6 : tester avec un agent
On peut demander à un agent :
Lis ce bundle OKF. Réponds uniquement à partir des concepts disponibles. Si une information manque, indique le concept à créer.
Ce test est très révélateur.
On voit vite si la base est réellement exploitable ou simplement jolie.
Étape 7 : gouverner
Il faut désigner :
- des propriétaires de concepts ;
- des règles de mise à jour ;
- des règles de validation ;
- des niveaux de confiance ;
- des règles de citation ;
- des processus de retrait ou de dépréciation.
Sans gouvernance, OKF deviendra un wiki de plus.
Et des wikis abandonnés, nous en avons déjà assez.
OKF et WordPress : une opportunité intéressante, mais attention
Pour un blog technologique, OKF ouvre une piste intéressante.
On peut imaginer publier, en plus des articles classiques, une couche de connaissance structurée pour les agents.
Par exemple, un blog pourrait proposer :
/okf/
├── index.md
├── articles/
│ ├── enterprise-brain.md
│ ├── open-knowledge-format.md
│ └── agents-et-connaissance.md
├── concepts/
│ ├── intelligence-collective.md
│ ├── knowledge-curation.md
│ ├── enterprise-brain.md
│ └── agentic-memory.md
└── series/
└── intelligence-collective.md
Chaque article pourrait être lié à des concepts.
Un agent qui lit le site ne verrait plus seulement une chronologie de publications. Il verrait une pensée structurée.
Et pour un blog d’expertise, c’est extrêmement intéressant.
Mais il faut faire attention : générer automatiquement un fichier OKF pour chaque article WordPress n’est pas suffisant.
Ce qui compte, ce n’est pas seulement d’avoir des fichiers Markdown.
Ce qui compte, c’est de faire émerger les concepts.
Un article peut contenir plusieurs concepts. Un concept peut traverser plusieurs articles. Une série peut faire évoluer une idée au fil du temps.
C’est cette couche conceptuelle qui a de la valeur.
Dans mon cas, par exemple, je pourrais imaginer des concepts comme :
- Enterprise Brain ;
- Intelligence collective ;
- Mémoire organisationnelle ;
- Agents métiers ;
- Knowledge as Code ;
- Context Engineering ;
- Agentic Governance ;
- Copilot comme interface cognitive ;
- Base de connaissance vivante ;
- Souveraineté de la connaissance.
Chaque nouvel article viendrait enrichir ces concepts, les relier, les préciser, parfois les contredire ou les faire évoluer.
Le blog ne serait plus seulement un flux éditorial.
Il deviendrait une base de pensée exploitable.
Pourquoi cela compte pour l’intelligence collective
Je reviens à l’idée centrale : l’intelligence collective n’est pas une réunion de plus, un atelier de brainstorming ou un outil collaboratif.
L’intelligence collective suppose une mémoire commune.
Sans mémoire commune, chaque groupe recommence les mêmes discussions, répète les mêmes erreurs, redécouvre les mêmes évidences et perd les mêmes décisions.
Les organisations sont pleines de conversations intelligentes qui ne deviennent jamais de la connaissance durable.
C’est probablement l’un des plus grands gaspillages du monde professionnel.
Nous produisons énormément de signaux : réunions, chats, documents, décisions, ateliers, formations, projets, incidents, retours clients.
Mais nous transformons mal ces signaux en connaissance structurée.
Les agents IA peuvent aider à faire ce travail. Mais encore faut-il leur donner une structure de destination.
OKF peut devenir cette structure.
Un agent peut écouter une réunion, extraire les décisions, mettre à jour une page de concept, ajouter une entrée dans le journal, signaler une contradiction avec une ancienne décision et proposer une révision à valider.
Ce n’est pas de la science-fiction. Techniquement, nous sommes déjà très proches de cela.
La difficulté n’est plus seulement technique. Elle est culturelle.
Sommes-nous prêts à traiter la connaissance comme un actif vivant ?
Sommes-nous prêts à maintenir nos concepts comme nous maintenons notre code ?
Sommes-nous prêts à accepter que la connaissance ait besoin de propriétaires, de versions, de tests, de revues et de dépréciations ?
Si la réponse est non, alors nos agents IA resteront des assistants brillants mais superficiels.
Si la réponse est oui, alors nous entrons dans une autre phase.
Ma lecture personnelle
Je vois OKF comme une petite pièce dans un puzzle beaucoup plus grand.
Depuis des années, je tourne autour de la même intuition : les organisations ont besoin d’un cerveau collectif mieux structuré.
Pas un cerveau magique. Pas une IA centrale qui déciderait pour tout le monde. Pas une boîte noire.
Un cerveau organisationnel composé de connaissances explicites, de liens, de décisions, de mémoires, de personnes, de processus, d’agents et d’outils.
OKF ne résout pas tout cela.
Mais OKF donne une forme concrète à une partie du problème : comment représenter la connaissance de manière suffisamment simple pour qu’elle soit maintenue par les humains et exploitée par les agents ?
Et cette question est capitale.
Parce que demain, la différence entre deux organisations ne se fera pas seulement sur le choix du modèle IA.
Tout le monde aura accès à de bons modèles.
La vraie différence se fera sur la qualité de la connaissance disponible autour du modèle.
Ce que l’organisation sait.
Ce qu’elle a su préserver.
Ce qu’elle a su structurer.
Ce qu’elle a su relier.
Ce qu’elle a su rendre actionnable.
L’intelligence artificielle ne remplacera pas la connaissance collective. Elle va révéler brutalement les organisations qui en ont une et celles qui n’en ont pas.
OKF est petit, mais le sujet est immense
L’Open Knowledge Format n’est pas impressionnant par sa complexité. Il est intéressant par sa simplicité.
Des dossiers. Des fichiers Markdown. Du YAML. Des liens. Des index. Des journaux de changement.
Rien de révolutionnaire, techniquement.
Mais parfois, les vraies révolutions commencent par des formats simples.
OKF nous rappelle une chose essentielle : les agents IA ne peuvent pas agir intelligemment dans une organisation qui ne sait pas représenter sa propre connaissance.
Nous avons passé des années à stocker des documents.
Il est temps de structurer des concepts.
Nous avons passé des années à chercher de l’information.
Il est temps de construire une mémoire.
Nous avons passé des années à parler d’intelligence collective.
Il est temps de lui donner une architecture.
OKF n’est peut-être qu’une première brique. Mais c’est une brique que je vais suivre de très près.
Parce qu’elle touche exactement au cœur du sujet : la rencontre entre connaissance, mémoire, agents et intelligence collective.
Et c’est probablement là que va se jouer la prochaine grande étape de l’IA en entreprise.








